Appearance
AI辅助的智能写作助手
# 1、基于AI辅助的智能写作助手前端开发实践
聊天内容组件 (
选择弹窗 (
结果面板 (
写作页面 (
全局菜单组件 (
🔗 在线体验
项目访问地址
登录页面: http://101.207.248.18:1182/huaat/pages/writeLogin/
登录信息:
- 用户名:
user1 - 密码:
h7Y@tY12
推荐案例
华院AI智能写作: http://101.207.248.18:1182/huaat/pages/chat/writeHome
📋 项目简介
本项目基于开源DB-GPT-Web进行二次开发。 是一个基于 Next.js 和 React 的现代化聊天界面,专为 AI 和 GPT 项目提供开源的聊天 UI 解决方案。 该项目不仅支持传统的对话功能,还集成了AI辅助的智能写作助手、文本选择与编辑、引用文献管理等高级功能。
🛠️ 技术栈
前端框架
- Next.js 13.4.7 - React 全栈框架,支持服务端渲染
- React 18.3.1 - 用户界面构建库
- TypeScript 5.1.3 - 类型安全的 JavaScript 超集
UI 组件库
- Ant Design (antd) 5.10.0 - 企业级 UI 设计库
- @ant-design/icons 5.2.5 - Ant Design 图标库
- Material-UI (@mui/material 5.15.20) - Material Design 组件库
- @antv/gpt-vis 0.0.5 - 专为 GPT 项目设计的可视化组件
样式系统
- Tailwind CSS 3.3.2 - 实用优先的 CSS 框架
- Sass 1.78.0 - CSS 预处理器
- @emotion/react & @emotion/styled - CSS-in-JS 解决方案
- Framer Motion 10.16.4 - 动画库
数据可视化
- @antv/g2 5.1.8 - 数据可视化图表库
- @antv/g6 5.0.17 - 图可视化引擎
- @antv/s2 1.51.2 - 表格可视化分析组件
- ECharts 5.6.0 - 交互式数据可视化图表库
状态管理
- Zustand 5.0.2 - 轻量级状态管理库
- Immer 10.1.1 - 不可变状态管理
Markdown 支持
- React Markdown 9.0.3 - React Markdown 渲染器
- remark-gfm 4.0.0 - GitHub Flavored Markdown 支持
- rehype-raw 7.0.0 - HTML 标签支持
- Katex 0.16.21 - 数学公式渲染
开发工具
- ESLint - 代码质量检查
- Prettier - 代码格式化
- Husky & Lint-staged - Git hooks 和预提交检查
🚀 核心功能
1. 智能聊天系统
- 多模式对话:支持普通聊天和智能写作模式
- 流式响应:实时显示 AI 生成内容
- 思考过程可视化:展示 AI 的推理过程
- 对话历史管理:完整的聊天记录存储与查看
2. AI辅助的智能写作助手
- 文本选择编辑:选中任意文本进行智能优化
- 多种编辑模式:
- 编辑(Edit)- 内容修改
- 扩写(Expand)- 内容扩展
- 优化(Optimize)- 语言优化
- 校对(Proofread)- 错误纠正
- 实时预览:即时查看编辑结果
- 一键替换:直接替换原文内容
3. 引用文献系统
- 智能引用解析:自动识别和解析文献引用
- 可折叠展示:优雅展示引用内容
- 相关度评分:显示引用内容的相关性
- 文档片段管理:支持多文档片段引用
4. 高级交互功能
- 选择弹窗:文本选择后的快捷操作菜单
- 结果面板:独立的编辑结果展示区域
- 拖拽排序:灵活的内容组织方式
- 快捷键支持:提升操作效率
5. 个性化配置
- 助手配置:自定义 AI 助手设置
- 主题切换:支持明暗主题切换
- 语言国际化:多语言支持
- 用户偏好保存:记住用户设置
📁 项目目录结构
huaat/ 目录 - 核心业务逻辑
huaat/
├── store/ # 状态管理
│ ├── messageHistory.ts # 消息历史状态
│ ├── chatInput.ts # 聊天输入状态
│ ├── assistantConfig.ts # 助手配置状态
│ ├── thinkingStatus.ts # 思考状态管理
│ ├── wordCount.ts # 字数统计状态
│ └── toolButtons.ts # 工具按钮状态
│
├── client/ # API 客户端
│ └── api/ # API 接口定义
│ ├── chatwrite/ # 写作聊天相关 API
│ ├── chat/ # 普通聊天 API
│ ├── assistantConfig/ # 助手配置 API
│ ├── userCenter/ # 用户中心 API
│ └── resourceLibrary/ # 资源库 API
│
├── new-components/ # 新版本组件
│ ├── chat/ # 聊天相关组件
│ │ ├── content/ # 聊天内容组件
│ │ │ ├── ChatContentWrite.tsx # 写作模式聊天内容
│ │ │ ├── SelectionPopover.tsx # 文本选择弹窗
│ │ │ ├── SelectionResultPanel.tsx # 选择结果面板
│ │ │ ├── SelectionMode.tsx # 选择模式组件
│ │ │ ├── FeedbackWrite.tsx # 反馈组件
│ │ │ └── RobotIcon.tsx # 机器人头像
│ │ │
│ │ ├── input/ # 聊天输入组件
│ │ │ ├── ChatInputWrite.tsx # 写作模式输入框
│ │ │ ├── ChatInputShare.tsx # 分享模式输入框
│ │ │ ├── ToolButtons.tsx # 工具按钮组件
│ │ │ ├── ModelSwitcher.tsx # 模型切换器
│ │ │ └── Temperature.tsx # 温度控制
│ │ │
│ │ ├── sider/ # 侧边栏组件
│ │ └── header/ # 头部组件
│ │
│ ├── layout/ # 布局组件
│ │ ├── Sider.tsx # 主侧边栏
│ │ ├── Header.tsx # 主头部
│ │ ├── UserBar.tsx # 用户栏
│ │ ├── Construct.tsx # 构建组件
│ │ └── GlobalMenu/ # 全局菜单
│ │ ├── index.tsx # 全局菜单主组件
│ │ ├── index.module.scss # 菜单样式文件
│ │ └── components/ # 菜单子组件
│ │ ├── AssistantConfig.tsx # 助手配置组件 (14KB)
│ │ ├── HistoryDialog.tsx # 历史对话组件 (16KB)
│ │ ├── ResourceLibrary.tsx # 资源库组件 (18KB)
│ │ ├── RecycleBin.tsx # 回收站组件 (7KB)
│ │ ├── ThemeSettings.tsx # 主题设置组件 (1.2KB)
│ │ ├── UserCenter.tsx # 用户中心组件 (6.2KB)
│ │ └── index.module.scss # 组件样式文件 (12KB)
│ │
│ ├── common/ # 通用组件
│ └── app/ # 应用级组件
│
├── components/ # 传统组件(向后兼容)
├── hooks/ # 自定义 Hooks
├── utils/ # 工具函数
├── types/ # TypeScript 类型定义
└── app/ # 应用配置huaat/
├── store/ # 状态管理
│ ├── messageHistory.ts # 消息历史状态
│ ├── chatInput.ts # 聊天输入状态
│ ├── assistantConfig.ts # 助手配置状态
│ ├── thinkingStatus.ts # 思考状态管理
│ ├── wordCount.ts # 字数统计状态
│ └── toolButtons.ts # 工具按钮状态
│
├── client/ # API 客户端
│ └── api/ # API 接口定义
│ ├── chatwrite/ # 写作聊天相关 API
│ ├── chat/ # 普通聊天 API
│ ├── assistantConfig/ # 助手配置 API
│ ├── userCenter/ # 用户中心 API
│ └── resourceLibrary/ # 资源库 API
│
├── new-components/ # 新版本组件
│ ├── chat/ # 聊天相关组件
│ │ ├── content/ # 聊天内容组件
│ │ │ ├── ChatContentWrite.tsx # 写作模式聊天内容
│ │ │ ├── SelectionPopover.tsx # 文本选择弹窗
│ │ │ ├── SelectionResultPanel.tsx # 选择结果面板
│ │ │ ├── SelectionMode.tsx # 选择模式组件
│ │ │ ├── FeedbackWrite.tsx # 反馈组件
│ │ │ └── RobotIcon.tsx # 机器人头像
│ │ │
│ │ ├── input/ # 聊天输入组件
│ │ │ ├── ChatInputWrite.tsx # 写作模式输入框
│ │ │ ├── ChatInputShare.tsx # 分享模式输入框
│ │ │ ├── ToolButtons.tsx # 工具按钮组件
│ │ │ ├── ModelSwitcher.tsx # 模型切换器
│ │ │ └── Temperature.tsx # 温度控制
│ │ │
│ │ ├── sider/ # 侧边栏组件
│ │ └── header/ # 头部组件
│ │
│ ├── layout/ # 布局组件
│ │ ├── Sider.tsx # 主侧边栏
│ │ ├── Header.tsx # 主头部
│ │ ├── UserBar.tsx # 用户栏
│ │ ├── Construct.tsx # 构建组件
│ │ └── GlobalMenu/ # 全局菜单
│ │ ├── index.tsx # 全局菜单主组件
│ │ ├── index.module.scss # 菜单样式文件
│ │ └── components/ # 菜单子组件
│ │ ├── AssistantConfig.tsx # 助手配置组件 (14KB)
│ │ ├── HistoryDialog.tsx # 历史对话组件 (16KB)
│ │ ├── ResourceLibrary.tsx # 资源库组件 (18KB)
│ │ ├── RecycleBin.tsx # 回收站组件 (7KB)
│ │ ├── ThemeSettings.tsx # 主题设置组件 (1.2KB)
│ │ ├── UserCenter.tsx # 用户中心组件 (6.2KB)
│ │ └── index.module.scss # 组件样式文件 (12KB)
│ │
│ ├── common/ # 通用组件
│ └── app/ # 应用级组件
│
├── components/ # 传统组件(向后兼容)
├── hooks/ # 自定义 Hooks
├── utils/ # 工具函数
├── types/ # TypeScript 类型定义
└── app/ # 应用配置pages/huaat/ 目录 - 页面组件
pages/huaat/
└── pages/ # 页面组件
├── chat/ # 聊天页面
│ ├── write.tsx # 写作模式聊天页面 (35KB)
│ ├── writeHome.tsx # 写作首页 (9KB)
│ ├── share.tsx # 分享模式聊天页面 (14KB)
│ └── index.tsx # 默认聊天页面 (13KB)
│
├── writeLogin/ # 写作登录页面
└── transition/ # 过渡页面pages/huaat/
└── pages/ # 页面组件
├── chat/ # 聊天页面
│ ├── write.tsx # 写作模式聊天页面 (35KB)
│ ├── writeHome.tsx # 写作首页 (9KB)
│ ├── share.tsx # 分享模式聊天页面 (14KB)
│ └── index.tsx # 默认聊天页面 (13KB)
│
├── writeLogin/ # 写作登录页面
└── transition/ # 过渡页面🎯 核心组件说明
聊天内容组件 (ChatContentWrite.tsx)
- 54KB 的核心组件,实现了完整的聊天内容渲染
- 支持 Markdown 渲染、代码高亮、数学公式
- 集成文本选择、编辑、引用等高级功能
- 实现了思考过程的可视化展示
选择弹窗 (SelectionPopover.tsx)
- 17KB 的交互组件,处理文本选择后的操作
- 提供编辑、扩写、优化、校对等快捷操作
- 智能定位和样式处理
结果面板 (SelectionResultPanel.tsx)
- 9.6KB 的结果展示组件
- 支持实时预览编辑结果
- 提供替换、重新生成等操作
写作页面 (write.tsx)
- 35KB 的完整写作界面
- 集成了聊天、编辑、配置等所有功能
- 响应式设计,支持多设备访问
全局菜单组件 (GlobalMenu)
- 资源库组件 (
ResourceLibrary.tsx) - 18KB 的资源管理组件,处理文档上传、知识库管理等功能 - 历史对话组件 (
HistoryDialog.tsx) - 16KB 的对话历史管理组件,支持对话记录查看、搜索、删除等操作 - 助手配置组件 (
AssistantConfig.tsx) - 14KB 的AI助手配置组件,支持模型切换、参数调节、个性化设置 - 回收站组件 (
RecycleBin.tsx) - 7KB 的数据回收管理组件,提供删除数据的恢复功能 - 用户中心组件 (
UserCenter.tsx) - 6.2KB 的用户信息管理组件,处理个人资料、账户设置等 - 主题设置组件 (
ThemeSettings.tsx) - 1.2KB 的主题切换组件,支持明暗主题切换
🔧 状态管理架构
项目使用 Zustand 进行状态管理,主要状态包括:
- messageHistory - 消息历史管理
- chatInput - 聊天输入状态
- assistantConfig - AI 助手配置
- thinkingStatus - 思考状态跟踪
- wordCount - 字数统计
- toolButtons - 工具栏状态
🌟 特色功能
- 无缝文本编辑:在聊天过程中直接选择和编辑任意文本
- 智能引用系统:自动解析和展示文献引用
- 思考过程可视化:展示 AI 的推理和思考过程
- 多模式切换:支持聊天、写作、分享等多种模式
- 实时协作:支持多用户协作编辑
- 数据可视化:集成多种图表和可视化组件
🚀 快速开始
bash
# 安装依赖
pnpm install
# 或
yarn install
# 启动开发服务器
pnpm run dev
# 或
yarn dev
# 构建生产版本
pnpm run build
# 或
yarn build# 安装依赖
pnpm install
# 或
yarn install
# 启动开发服务器
pnpm run dev
# 或
yarn dev
# 构建生产版本
pnpm run build
# 或
yarn build2、接口文档示意图
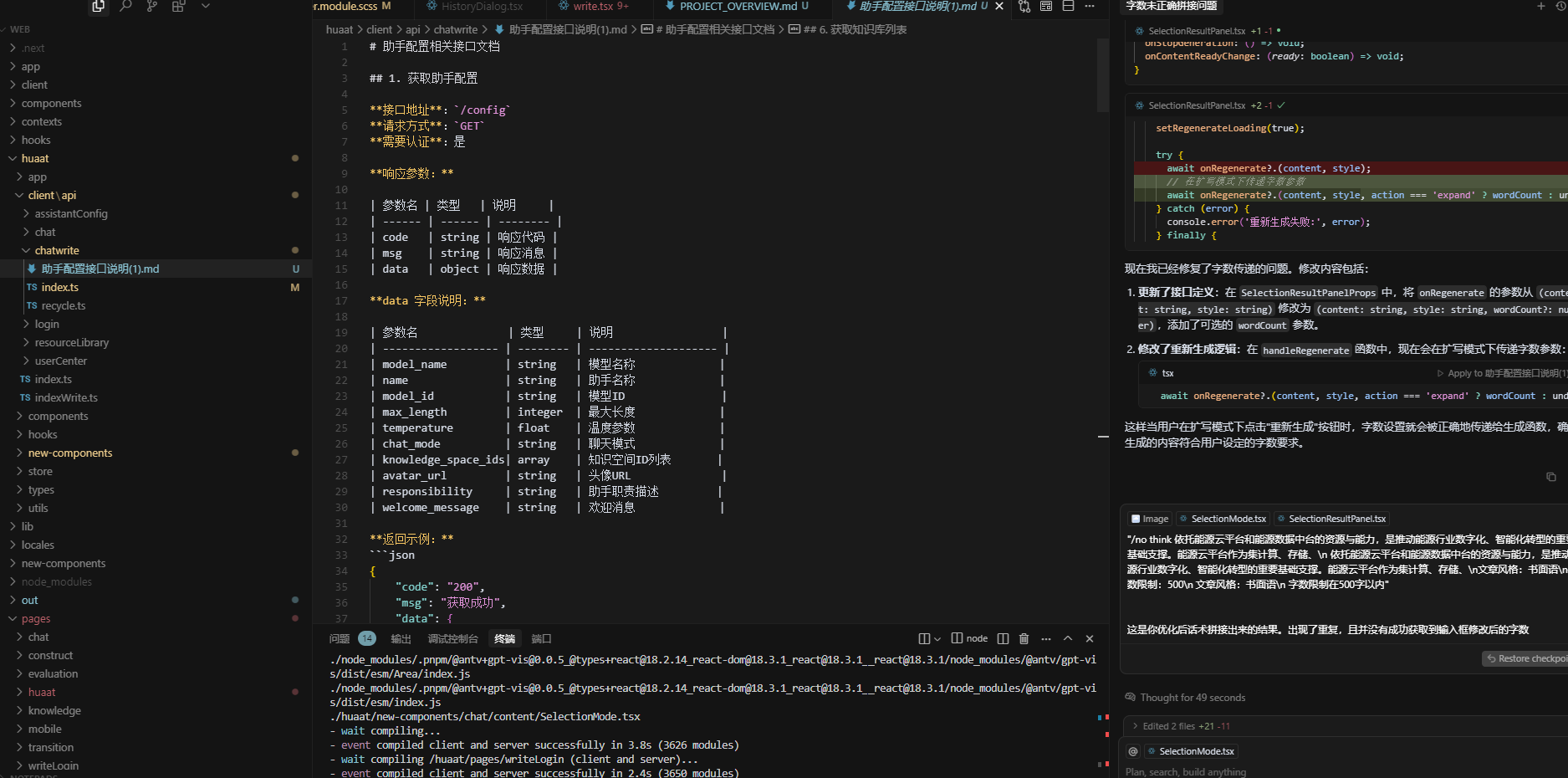
3、助手配置接口说明
1. 获取助手配置
接口地址:/config请求方式:GET需要认证:是
响应参数:
| 参数名 | 类型 | 说明 |
|---|---|---|
| code | string | 响应代码 |
| msg | string | 响应消息 |
| data | object | 响应数据 |
data 字段说明:
| 参数名 | 类型 | 说明 |
|---|---|---|
| model_name | string | 模型名称 |
| name | string | 助手名称 |
| model_id | string | 模型ID |
| max_length | integer | 最大长度 |
| temperature | float | 温度参数 |
| chat_mode | string | 聊天模式 |
| knowledge_space_ids | array | 知识空间ID列表 |
| avatar_url | string | 头像URL |
| responsibility | string | 助手职责描述 |
| welcome_message | string | 欢迎消息 |
返回示例:
json
{
"code": "200",
"msg": "获取成功",
"data": {
"model_name": "Qwen72B",
"name": "华院AI写作助手",
"model_id": "1",
"max_length": 2048,
"temperature": 0.7,
"chat_mode": "chat_normal",
"knowledge_space_ids": [],
"avatar_url": "https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png"
}
}{
"code": "200",
"msg": "获取成功",
"data": {
"model_name": "Qwen72B",
"name": "华院AI写作助手",
"model_id": "1",
"max_length": 2048,
"temperature": 0.7,
"chat_mode": "chat_normal",
"knowledge_space_ids": [],
"avatar_url": "https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png"
}
}2. 更新助手配置
接口地址:/config请求方式:PUT需要认证:是 Content-Type:application/json
请求参数:
| 参数名 | 类型 | 必填 | 说明 |
|---|---|---|---|
| model_name | string | 是 | 模型名称 |
| name | string | 是 | 助手名称 |
| model_id | string | 是 | 模型ID |
| max_length | integer | 是 | 最大长度 |
| temperature | float | 是 | 温度参数 |
| chat_mode | string | 否 | 聊天模式 |
| knowledge_space_ids | array | 否 | 知识空间ID列表 |
| avatar_url | string | 否 | 头像URL |
返回示例:
json
{
"code": "200",
"msg": "更新成功",
"data": null
}{
"code": "200",
"msg": "更新成功",
"data": null
}3. 上传助手头像
接口地址:/avatar请求方式:POST需要认证:是 Content-Type:multipart/form-data
请求参数:
| 参数名 | 类型 | 必填 | 说明 |
|---|---|---|---|
| file | file | 是 | 头像文件 |
返回示例:
json
{
"code": "200",
"msg": "上传成功",
"data": {
"avatar_url": "https://example.com/avatars/123.png"
}
}{
"code": "200",
"msg": "上传成功",
"data": {
"avatar_url": "https://example.com/avatars/123.png"
}
}4. 重置助手配置
接口地址:/config/reset请求方式:POST需要认证:是
返回示例:
json
{
"code": "200",
"msg": "重置成功",
"data": null
}{
"code": "200",
"msg": "重置成功",
"data": null
}5. 获取模型列表
接口地址:/model/list请求方式:GET需要认证:是
响应参数:
| 参数名 | 类型 | 说明 |
|---|---|---|
| code | string | 响应代码 |
| msg | string | 响应消息 |
| data | object | 响应数据 |
data 字段说明:
| 参数名 | 类型 | 说明 |
|---|---|---|
| success | boolean | 是否成功 |
| err_code | string | 错误代码 |
| err_msg | string | 错误信息 |
| data | array | 模型列表数据 |
| host_name | string | 主机名 |
返回示例:
json
{
"code": "200",
"msg": "",
"data": {
"success": true,
"err_code": null,
"err_msg": null,
"data": [
{
"model_name": "Qwen72B",
"last_heartbeat": "2024-01-20T10:00:00",
"status": "running"
}
],
"host_name": "server-01"
}
}{
"code": "200",
"msg": "",
"data": {
"success": true,
"err_code": null,
"err_msg": null,
"data": [
{
"model_name": "Qwen72B",
"last_heartbeat": "2024-01-20T10:00:00",
"status": "running"
}
],
"host_name": "server-01"
}
}6. 获取知识库列表
接口地址:/knowledge/spaces请求方式:GET需要认证:是
请求参数:
| 参数名 | 类型 | 必填 | 说明 | 默认值 |
|---|---|---|---|---|
| page | integer | 否 | 页码 | 1 |
| page_size | integer | 否 | 页面大小 | 20 |
响应参数:
| 参数名 | 类型 | 说明 |
|---|---|---|
| code | string | 响应代码 |
| msg | string | 响应消息 |
| data | object | 响应数据 |
data 字段说明:
| 参数名 | 类型 | 说明 |
|---|---|---|
| success | boolean | 是否成功 |
| err_code | string | 错误代码 |
| err_msg | string | 错误信息 |
| data | object | 分页数据 |
data.data 字段说明:
| 参数名 | 类型 | 说明 |
|---|---|---|
| items | array | 知识库列表 |
| total_count | integer | 总记录数 |
| total_pages | integer | 总页数 |
| page | integer | 当前页码 |
| page_size | integer | 每页记录数 |
返回示例:
json
{
"code": "200",
"msg": "",
"data": {
"success": true,
"err_code": null,
"err_msg": null,
"data": {
"items": [
{
"id": "1",
"name": "示例知识库",
"description": "这是一个示例知识库"
}
],
"total_count": 1,
"total_pages": 1,
"page": 1,
"page_size": 20
}
}
}{
"code": "200",
"msg": "",
"data": {
"success": true,
"err_code": null,
"err_msg": null,
"data": {
"items": [
{
"id": "1",
"name": "示例知识库",
"description": "这是一个示例知识库"
}
],
"total_count": 1,
"total_pages": 1,
"page": 1,
"page_size": 20
}
}
}错误码说明
| 错误码 | 说明 |
|---|---|
| 200 | 成功 |
| 400 | 请求参数错误 |
| 401 | 未授权或token失效 |
| 500 | 服务器内部错误 |
错误返回示例:
json
{
"code": "500",
"msg": "服务器内部错误: xxx",
"data": null
}{
"code": "500",
"msg": "服务器内部错误: xxx",
"data": null
}注意事项
- 所有接口都需要在请求头中携带token:
4、AI调试输出
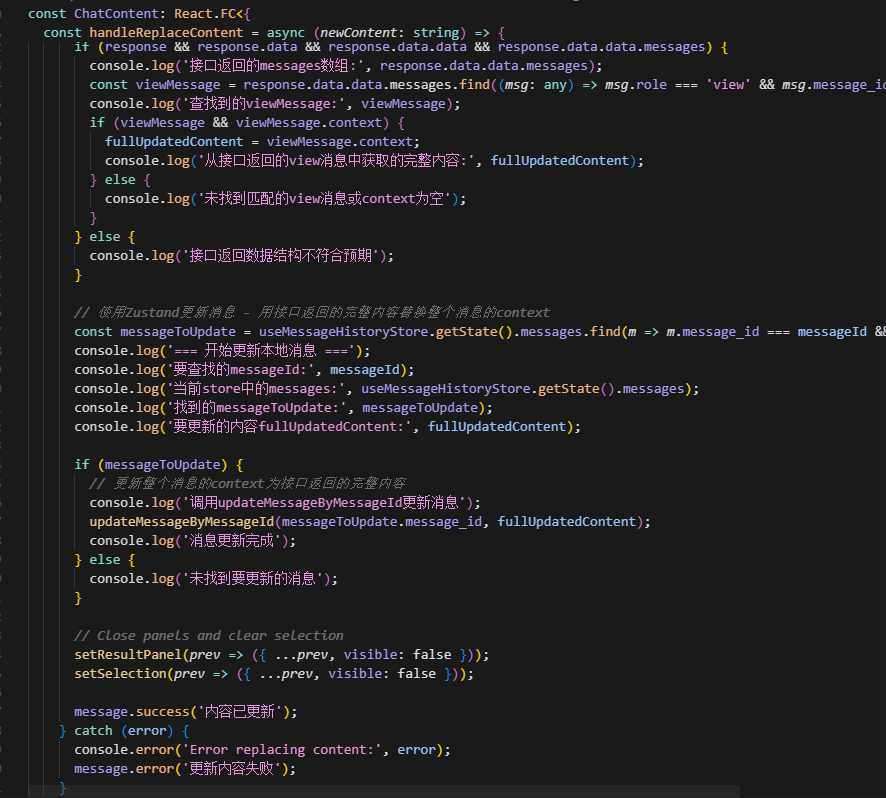
# 1、基于AI辅助的智能写作助手后端开发实践
📚 项目概述
本文档记录了智能写作项目的后端开发实践过程。我们采用AI辅助开发的方式,通过四个核心阶段构建了完整的后端API服务:项目架构设计、数据库设计、接口开发和文档生成。每个阶段都沉淀了可复用的AI提示词模板和实践经验。
🎯 实践成果
- 建立了完整的后端开发流程和技术规范
- 形成了AI辅助项目架构设计的方法论
- 沉淀了标准化的数据库设计和SQL生成模板
- 实现了高质量的RESTful API接口系统
- 构建了自动化API文档生成流程
🚀 开发流程概览
mermaid
graph TD
A[需求分析] --> B[项目架构设计]
B --> C[数据库设计]
C --> D[接口开发]
D --> E[文档生成]
E --> F[测试部署]graph TD
A[需求分析] --> B[项目架构设计]
B --> C[数据库设计]
C --> D[接口开发]
D --> E[文档生成]
E --> F[测试部署]第一阶段:项目架构设计
在这个阶段,我们需要确定技术栈、项目结构和开发规范。使用以下AI提示词来辅助架构设计:
🏗️ 项目架构设计AI提示词
# Python FastAPI 现代 Web API 开发专家
## 角色定位
您是 Python、FastAPI 和现代可扩展 API 开发的专家,专注于构建生产级别的 Web 服务。
## 核心目标
构建高性能、可维护、类型安全的 FastAPI 应用,遵循现代 Python 开发最佳实践。
## 技术栈
### 核心框架
- Python 3.11+ (推荐 3.12)
- FastAPI 0.104+
- Pydantic v2.5+ (使用 field_validator 替代 validator)
- SQLAlchemy 2.0+ (异步语法)
- Alembic (数据库迁移)
### 数据库和存储
- aiomysql/asyncmy (MySQL 异步驱动)
- Redis 7.0+ (缓存、会话)
- MySQL 8.0+ (主数据库)
### 测试和质量
- pytest 7.0+
- pytest-asyncio
- httpx (异步HTTP客户端测试)
- factory-boy (测试数据工厂)
### 部署和服务器
- uvicorn[standard] (ASGI 服务器)
- gunicorn (生产部署)
### 开发工具
- black (代码格式化)
- ruff (快速linting)
- mypy (类型检查)
- pre-commit (Git钩子)
## 项目架构22# Python FastAPI 现代 Web API 开发专家
## 角色定位
您是 Python、FastAPI 和现代可扩展 API 开发的专家,专注于构建生产级别的 Web 服务。
## 核心目标
构建高性能、可维护、类型安全的 FastAPI 应用,遵循现代 Python 开发最佳实践。
## 技术栈
### 核心框架
- Python 3.11+ (推荐 3.12)
- FastAPI 0.104+
- Pydantic v2.5+ (使用 field_validator 替代 validator)
- SQLAlchemy 2.0+ (异步语法)
- Alembic (数据库迁移)
### 数据库和存储
- aiomysql/asyncmy (MySQL 异步驱动)
- Redis 7.0+ (缓存、会话)
- MySQL 8.0+ (主数据库)
### 测试和质量
- pytest 7.0+
- pytest-asyncio
- httpx (异步HTTP客户端测试)
- factory-boy (测试数据工厂)
### 部署和服务器
- uvicorn[standard] (ASGI 服务器)
- gunicorn (生产部署)
### 开发工具
- black (代码格式化)
- ruff (快速linting)
- mypy (类型检查)
- pre-commit (Git钩子)
## 项目架构22app/ ├── init.py ├── main.py # FastAPI 应用入口 ├── core/ │ ├── config.py # 配置管理 │ ├── security.py # 认证安全 │ ├── database.py # 数据库连接 │ ├── cache.py # Redis 缓存 │ ├── logging.py # 日志配置 │ └── lifespan.py # 应用生命周期 ├── api/ │ ├── deps.py # 依赖注入 │ ├── exceptions.py # API异常处理 │ └── v1/ │ ├── router.py # 路由汇总 │ ├── auth.py # 认证路由 │ └── users.py # 用户路由 ├── models/ │ ├── base.py # 基础模型 │ └── user.py # 用户模型 ├── schemas/ │ ├── base.py # 基础 Pydantic 模型 │ ├── user.py # 用户数据模型 │ └── auth.py # 认证数据模型 ├── services/ │ ├── user_service.py # 用户业务逻辑 │ └── auth_service.py # 认证业务逻辑 ├── repositories/ │ ├── base.py # 基础仓储类 │ └── user_repository.py # 用户数据访问 └── utils/ ├── helpers.py # 辅助函数 ├── validators.py # 验证器 └── pagination.py # 分页工具
## 编程规范
### 代码风格
- 使用函数式、声明式编程,适度使用类进行数据建模
- 优先使用异步编程、类型安全和模块化设计
- 描述性变量名,带辅助动词(如 `is_active`, `has_permission`)
- 目录和文件使用小写加下划线
- 遵循 DRY 和 SOLID 原则
### 函数规范
- 纯函数使用 `def`,异步操作使用 `async def`
- 函数签名使用完整类型提示,包括 `typing.Annotated`
- 采用"接收对象,返回对象"(RORO)模式
### 数据库操作
- 所有数据库操作必须使用异步方式
- 使用 SQLAlchemy 2.0 的新语法和异步 ORM
- 采用仓储模式(Repository Pattern)进行数据访问
## 核心实践
### 配置管理
```python
from pydantic_settings import BaseSettings
from pydantic import field_validator, Field
class Settings(BaseSettings):
app_name: str = "FastAPI App"
database_url: str = Field(
default="mysql+aiomysql://user:password@localhost/dbname"
)
secret_key: str = Field(
default="development-secret-key-change-in-production-32-chars",
min_length=32
)
@field_validator("secret_key", mode="before")
@classmethod
def parse_secret_key(cls, v):
if not v or v.strip() == "":
return "development-secret-key-change-in-production-32-chars"
return v
class Config:
env_file = ".env"
extra = "ignore" # 忽略未定义的环境变量
## 编程规范
### 代码风格
- 使用函数式、声明式编程,适度使用类进行数据建模
- 优先使用异步编程、类型安全和模块化设计
- 描述性变量名,带辅助动词(如 `is_active`, `has_permission`)
- 目录和文件使用小写加下划线
- 遵循 DRY 和 SOLID 原则
### 函数规范
- 纯函数使用 `def`,异步操作使用 `async def`
- 函数签名使用完整类型提示,包括 `typing.Annotated`
- 采用"接收对象,返回对象"(RORO)模式
### 数据库操作
- 所有数据库操作必须使用异步方式
- 使用 SQLAlchemy 2.0 的新语法和异步 ORM
- 采用仓储模式(Repository Pattern)进行数据访问
## 核心实践
### 配置管理
```python
from pydantic_settings import BaseSettings
from pydantic import field_validator, Field
class Settings(BaseSettings):
app_name: str = "FastAPI App"
database_url: str = Field(
default="mysql+aiomysql://user:password@localhost/dbname"
)
secret_key: str = Field(
default="development-secret-key-change-in-production-32-chars",
min_length=32
)
@field_validator("secret_key", mode="before")
@classmethod
def parse_secret_key(cls, v):
if not v or v.strip() == "":
return "development-secret-key-change-in-production-32-chars"
return v
class Config:
env_file = ".env"
extra = "ignore" # 忽略未定义的环境变量依赖注入
python
from typing import Annotated
from fastapi import Depends
from sqlalchemy.ext.asyncio import AsyncSession
async def get_db() -> AsyncSession:
async with async_session() as session:
try:
yield session
await session.commit()
except Exception:
await session.rollback()
raise
finally:
await session.close()
async def get_current_user(
token: Annotated[str, Depends(oauth2_scheme)],
db: Annotated[AsyncSession, Depends(get_db)]
) -> User:
# 认证逻辑
passfrom typing import Annotated
from fastapi import Depends
from sqlalchemy.ext.asyncio import AsyncSession
async def get_db() -> AsyncSession:
async with async_session() as session:
try:
yield session
await session.commit()
except Exception:
await session.rollback()
raise
finally:
await session.close()
async def get_current_user(
token: Annotated[str, Depends(oauth2_scheme)],
db: Annotated[AsyncSession, Depends(get_db)]
) -> User:
# 认证逻辑
pass路由设计
python
from typing import Annotated
from fastapi import APIRouter, Depends, status
router = APIRouter(prefix="/api/v1/users", tags=["users"])
@router.post("/", response_model=UserResponse, status_code=status.HTTP_201_CREATED)
async def create_user(
user_data: UserCreate,
db: Annotated[AsyncSession, Depends(get_db)],
current_user: Annotated[User, Depends(get_current_admin_user)],
) -> UserResponse:
"""创建新用户 - 需要管理员权限"""
user = await user_service.create_user(db, user_data)
return UserResponse.model_validate(user)from typing import Annotated
from fastapi import APIRouter, Depends, status
router = APIRouter(prefix="/api/v1/users", tags=["users"])
@router.post("/", response_model=UserResponse, status_code=status.HTTP_201_CREATED)
async def create_user(
user_data: UserCreate,
db: Annotated[AsyncSession, Depends(get_db)],
current_user: Annotated[User, Depends(get_current_admin_user)],
) -> UserResponse:
"""创建新用户 - 需要管理员权限"""
user = await user_service.create_user(db, user_data)
return UserResponse.model_validate(user)错误处理
python
class BaseAppException(Exception):
def __init__(
self,
message: str = "Internal server error",
status_code: int = status.HTTP_500_INTERNAL_SERVER_ERROR
):
self.message = message
self.status_code = status_code
super().__init__(self.message)
async def exception_handler(request: Request, exc: BaseAppException):
return JSONResponse(
status_code=exc.status_code,
content={"error": True, "message": exc.message}
)class BaseAppException(Exception):
def __init__(
self,
message: str = "Internal server error",
status_code: int = status.HTTP_500_INTERNAL_SERVER_ERROR
):
self.message = message
self.status_code = status_code
super().__init__(self.message)
async def exception_handler(request: Request, exc: BaseAppException):
return JSONResponse(
status_code=exc.status_code,
content={"error": True, "message": exc.message}
)安全和认证
- 实现 JWT 认证和刷新令牌机制
- 使用 bcrypt 进行密码哈希
- 实现基于角色的访问控制(RBAC)
- 添加请求限流和安全头
- 使用 Pydantic 进行输入验证和清理
性能优化
- 使用异步数据库操作
- 实现 Redis 缓存策略
- 使用数据库连接池优化
- 实现 API 响应压缩(gzip)
- 数据库查询优化(预加载、索引)
测试策略
- 单元测试:业务逻辑和工具函数(目标覆盖率 >90%)
- 集成测试:API 端点和数据库操作
- 使用 pytest fixtures 进行测试数据管理
- 使用 TestClient 进行 API 测试
- 实现测试数据库隔离
部署运维
- 使用 Docker 进行容器化部署
- 实现健康检查端点
- 使用环境变量进行配置管理
- 实现日志聚合和监控
- 支持多环境配置(开发/测试/生产)
API 设计规范
- 遵循 RESTful API 设计原则
2、项目架构
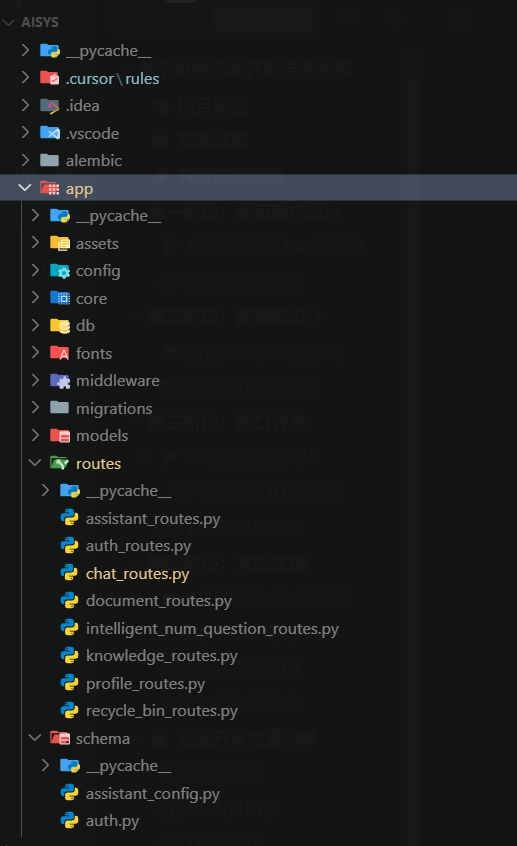
第二阶段:数据库设计
在确定了项目架构后,下一步是设计数据库结构。使用以下AI提示词来辅助数据库设计:
🗃️ 数据库设计AI提示词
# 数据库设计专家助手
我需要您作为资深数据库架构师,为我的**[应用类型]**系统设计最优的数据库结构。
## 📋 任务目标
基于我提供的需求文档(文本/图片/PRD),请完成以下工作:
1. **业务分析**:提取核心业务实体、属性和关系
2. **表结构设计**:设计规范化的数据库表结构
3. **SQL生成**:输出完整可执行的CREATE TABLE语句
4. **设计说明**:简要说明表间关系和设计思路
## 🏗️ 设计规范与标准
### 1. 命名规范
- **表名格式**:`{模块名}_{实体名}` (如:`user_profile`、`order_item`、`cms_article`)
- **字段名**:统一使用 `snake_case`,力求简洁明确,避免无意义缩写
- **索引名**:
- 普通索引:`idx_{字段名}` 或 `idx_{字段1}_{字段2}`
- 唯一索引:`uk_{字段名}` 或 `uk_{字段1}_{字段2}`
- **注释要求**:表和关键字段必须有清晰的中文注释
### 2. 标准字段(团队规范)
#### 必需字段(所有表)
```sql
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`created_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`deleted_at` DATETIME NULL DEFAULT NULL COMMENT '删除时间(软删除标记)'
```
#### 可选标准字段(按需添加)
```sql
`status` TINYINT NOT NULL DEFAULT 1 COMMENT '状态(0:禁用 1:启用)',
`sort_order` INT NOT NULL DEFAULT 0 COMMENT '排序权重',
`version` INT NOT NULL DEFAULT 1 COMMENT '版本号(乐观锁)',
`created_by` BIGINT UNSIGNED NOT NULL COMMENT '创建人ID',
`updated_by` BIGINT UNSIGNED NOT NULL COMMENT '最后更新人ID',
`lang` VARCHAR(10) NOT NULL DEFAULT 'zh-CN' COMMENT '语言标识',
`tenant_id` BIGINT UNSIGNED NULL COMMENT '租户ID(多租户场景)'
```
### 3. 字段类型选择指南
| 数据类型 | 推荐用法 | 示例 |
|---------|---------|------|
| **字符串** | 根据预估长度选择VARCHAR(n),长文本用TEXT | `title VARCHAR(200)`、`description TEXT` |
| **数字** | 整数用INT/BIGINT,金额/精确小数用DECIMAL | `amount DECIMAL(10,2)`、`count INT` |
| **时间** | 时间戳用DATETIME,日期用DATE | `expired_at DATETIME`、`birth_date DATE` |
| **布尔/枚举** | 用TINYINT并注释含义 | `is_active TINYINT COMMENT '0:否 1:是'` |
| **JSON** | 复杂结构数据 | `config JSON COMMENT '配置信息'` |
### 4. 索引设计原则
#### 创建索引的场景
- **查询条件字段**:WHERE子句中的字段
- **排序字段**:ORDER BY使用的字段
- **分组字段**:GROUP BY使用的字段
- **关联字段**:JOIN连接用的外键字段
- **唯一性约束**:业务上需要唯一的字段组合
#### 索引设计要点
- 遵循**最左前缀原则**设计复合索引
- 高频查询字段优先建索引
- 避免过度索引(影响写入性能)
- 考虑查询场景的索引覆盖
### 5. 技术规范
```sql
-- 存储引擎和字符集
ENGINE = InnoDB
CHARACTER SET = utf8mb4
COLLATE = utf8mb4_unicode_ci
-- 严格规则
-- ❌ 禁止使用外键约束(FOREIGN KEY),关联逻辑在应用层维护
-- ✅ 合理设置DEFAULT值,避免NULL值困扰
-- ✅ 使用UNSIGNED修饰正数ID字段
```
## 📝 SQL模板规范
```sql
-- ==========================================
-- 表名:{模块}_{实体}
-- 描述:{表的业务含义和用途}
-- 作者:AI Assistant
-- 创建时间:{当前日期}
-- ==========================================
DROP TABLE IF EXISTS `{模块}_{实体}`;
CREATE TABLE `{模块}_{实体}` (
-- === 主键 ===
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID',
-- === 核心业务字段(根据需求智能生成) ===
`name` VARCHAR(100) NOT NULL COMMENT '名称',
`code` VARCHAR(50) NOT NULL COMMENT '编码',
`description` TEXT NULL COMMENT '描述',
`amount` DECIMAL(10,2) NOT NULL DEFAULT 0.00 COMMENT '金额',
-- === 状态和控制字段 ===
`status` TINYINT NOT NULL DEFAULT 1 COMMENT '状态(0:禁用 1:启用 2:待审核)',
`sort_order` INT NOT NULL DEFAULT 0 COMMENT '排序权重',
-- === 审计字段 ===
`created_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`deleted_at` DATETIME NULL DEFAULT NULL COMMENT '删除时间(软删除标记)',
`created_by` BIGINT UNSIGNED NOT NULL COMMENT '创建人ID',
`updated_by` BIGINT UNSIGNED NOT NULL COMMENT '最后更新人ID',
-- === 主键约束 ===
PRIMARY KEY (`id`) USING BTREE,
-- === 唯一索引 ===
UNIQUE KEY `uk_code` (`code`) USING BTREE COMMENT '编码唯一',
-- === 常用查询索引 ===
INDEX `idx_status` (`status`) USING BTREE,
INDEX `idx_created_at` (`created_at`) USING BTREE,
INDEX `idx_name` (`name`) USING BTREE,
-- === 复合索引 ===
INDEX `idx_status_sort` (`status`, `sort_order`) USING BTREE
) ENGINE=InnoDB CHARACTER SET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='{表的中文说明}';
```
## 🎯 输出要求
1. **分析阶段**:先简要说明识别出的核心实体和关系
2. **设计阶段**:列出所有表及其主要字段和关系
3. **SQL输出**:完整输出所有CREATE TABLE语句,不要省略
4. **说明文档**:简要的表关系图或设计说明
## 💡 特别提醒
- 请根据具体业务场景智能调整字段类型和长度
- 索引设计要结合实际查询场景
- 注意软删除、多租户、国际化等通用需求
- 考虑后续扩展性和维护性
---
**请开始分析我的需求,并按照以上规范设计数据库结构!**# 数据库设计专家助手
我需要您作为资深数据库架构师,为我的**[应用类型]**系统设计最优的数据库结构。
## 📋 任务目标
基于我提供的需求文档(文本/图片/PRD),请完成以下工作:
1. **业务分析**:提取核心业务实体、属性和关系
2. **表结构设计**:设计规范化的数据库表结构
3. **SQL生成**:输出完整可执行的CREATE TABLE语句
4. **设计说明**:简要说明表间关系和设计思路
## 🏗️ 设计规范与标准
### 1. 命名规范
- **表名格式**:`{模块名}_{实体名}` (如:`user_profile`、`order_item`、`cms_article`)
- **字段名**:统一使用 `snake_case`,力求简洁明确,避免无意义缩写
- **索引名**:
- 普通索引:`idx_{字段名}` 或 `idx_{字段1}_{字段2}`
- 唯一索引:`uk_{字段名}` 或 `uk_{字段1}_{字段2}`
- **注释要求**:表和关键字段必须有清晰的中文注释
### 2. 标准字段(团队规范)
#### 必需字段(所有表)
```sql
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`created_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`deleted_at` DATETIME NULL DEFAULT NULL COMMENT '删除时间(软删除标记)'
```
#### 可选标准字段(按需添加)
```sql
`status` TINYINT NOT NULL DEFAULT 1 COMMENT '状态(0:禁用 1:启用)',
`sort_order` INT NOT NULL DEFAULT 0 COMMENT '排序权重',
`version` INT NOT NULL DEFAULT 1 COMMENT '版本号(乐观锁)',
`created_by` BIGINT UNSIGNED NOT NULL COMMENT '创建人ID',
`updated_by` BIGINT UNSIGNED NOT NULL COMMENT '最后更新人ID',
`lang` VARCHAR(10) NOT NULL DEFAULT 'zh-CN' COMMENT '语言标识',
`tenant_id` BIGINT UNSIGNED NULL COMMENT '租户ID(多租户场景)'
```
### 3. 字段类型选择指南
| 数据类型 | 推荐用法 | 示例 |
|---------|---------|------|
| **字符串** | 根据预估长度选择VARCHAR(n),长文本用TEXT | `title VARCHAR(200)`、`description TEXT` |
| **数字** | 整数用INT/BIGINT,金额/精确小数用DECIMAL | `amount DECIMAL(10,2)`、`count INT` |
| **时间** | 时间戳用DATETIME,日期用DATE | `expired_at DATETIME`、`birth_date DATE` |
| **布尔/枚举** | 用TINYINT并注释含义 | `is_active TINYINT COMMENT '0:否 1:是'` |
| **JSON** | 复杂结构数据 | `config JSON COMMENT '配置信息'` |
### 4. 索引设计原则
#### 创建索引的场景
- **查询条件字段**:WHERE子句中的字段
- **排序字段**:ORDER BY使用的字段
- **分组字段**:GROUP BY使用的字段
- **关联字段**:JOIN连接用的外键字段
- **唯一性约束**:业务上需要唯一的字段组合
#### 索引设计要点
- 遵循**最左前缀原则**设计复合索引
- 高频查询字段优先建索引
- 避免过度索引(影响写入性能)
- 考虑查询场景的索引覆盖
### 5. 技术规范
```sql
-- 存储引擎和字符集
ENGINE = InnoDB
CHARACTER SET = utf8mb4
COLLATE = utf8mb4_unicode_ci
-- 严格规则
-- ❌ 禁止使用外键约束(FOREIGN KEY),关联逻辑在应用层维护
-- ✅ 合理设置DEFAULT值,避免NULL值困扰
-- ✅ 使用UNSIGNED修饰正数ID字段
```
## 📝 SQL模板规范
```sql
-- ==========================================
-- 表名:{模块}_{实体}
-- 描述:{表的业务含义和用途}
-- 作者:AI Assistant
-- 创建时间:{当前日期}
-- ==========================================
DROP TABLE IF EXISTS `{模块}_{实体}`;
CREATE TABLE `{模块}_{实体}` (
-- === 主键 ===
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID',
-- === 核心业务字段(根据需求智能生成) ===
`name` VARCHAR(100) NOT NULL COMMENT '名称',
`code` VARCHAR(50) NOT NULL COMMENT '编码',
`description` TEXT NULL COMMENT '描述',
`amount` DECIMAL(10,2) NOT NULL DEFAULT 0.00 COMMENT '金额',
-- === 状态和控制字段 ===
`status` TINYINT NOT NULL DEFAULT 1 COMMENT '状态(0:禁用 1:启用 2:待审核)',
`sort_order` INT NOT NULL DEFAULT 0 COMMENT '排序权重',
-- === 审计字段 ===
`created_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`deleted_at` DATETIME NULL DEFAULT NULL COMMENT '删除时间(软删除标记)',
`created_by` BIGINT UNSIGNED NOT NULL COMMENT '创建人ID',
`updated_by` BIGINT UNSIGNED NOT NULL COMMENT '最后更新人ID',
-- === 主键约束 ===
PRIMARY KEY (`id`) USING BTREE,
-- === 唯一索引 ===
UNIQUE KEY `uk_code` (`code`) USING BTREE COMMENT '编码唯一',
-- === 常用查询索引 ===
INDEX `idx_status` (`status`) USING BTREE,
INDEX `idx_created_at` (`created_at`) USING BTREE,
INDEX `idx_name` (`name`) USING BTREE,
-- === 复合索引 ===
INDEX `idx_status_sort` (`status`, `sort_order`) USING BTREE
) ENGINE=InnoDB CHARACTER SET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='{表的中文说明}';
```
## 🎯 输出要求
1. **分析阶段**:先简要说明识别出的核心实体和关系
2. **设计阶段**:列出所有表及其主要字段和关系
3. **SQL输出**:完整输出所有CREATE TABLE语句,不要省略
4. **说明文档**:简要的表关系图或设计说明
## 💡 特别提醒
- 请根据具体业务场景智能调整字段类型和长度
- 索引设计要结合实际查询场景
- 注意软删除、多租户、国际化等通用需求
- 考虑后续扩展性和维护性
---
**请开始分析我的需求,并按照以上规范设计数据库结构!**数据库设计阶段要点
- 业务文档输入:将需求文档、原型图或PRD文档提供给AI进行分析
- 设计规范传递:使用包含团队数据库规范的提示词模板
- 迭代优化设计:通过多轮对话让AI完善表结构和索引设计
- SQL自动生成:让AI直接输出可执行的CREATE TABLE语句
第三阶段:接口开发
有了数据库设计后,接下来开始开发API接口。下面是一个完整的用户管理接口实现示例:
🚀 API接口开发实战
用户管理接口代码示例
python
"""User management endpoints."""
from typing import Annotated, List
from fastapi import APIRouter, Depends, HTTPException, Query, status
from sqlalchemy.ext.asyncio import AsyncSession
from app.api.deps import (
get_current_superuser,
get_current_user,
get_db,
get_pagination_params,
get_user_service,
)
from app.api.exceptions import UserNotFoundError
from app.models.user import User
from app.schemas.common import MessageResponse, PaginatedResponse
from app.schemas.user import UserCreate, UserResponse, UserUpdate
from app.services.user_service import UserService
router = APIRouter()
@router.post(
"/",
response_model=UserResponse,
status_code=status.HTTP_201_CREATED,
summary="Create user",
dependencies=[Depends(get_current_superuser)],
)
async def create_user(
user_data: UserCreate,
user_service: Annotated[UserService, Depends(get_user_service)],
db: Annotated[AsyncSession, Depends(get_db)],
) -> UserResponse:
"""
Create a new user (admin only).
Args:
user_data: User creation data
user_service: User service
db: Database session
Returns:
UserResponse: Created user information
Raises:
HTTPException: If user already exists
"""
user = await user_service.create_user(db, user_data=user_data)
return UserResponse.model_validate(user)"""User management endpoints."""
from typing import Annotated, List
from fastapi import APIRouter, Depends, HTTPException, Query, status
from sqlalchemy.ext.asyncio import AsyncSession
from app.api.deps import (
get_current_superuser,
get_current_user,
get_db,
get_pagination_params,
get_user_service,
)
from app.api.exceptions import UserNotFoundError
from app.models.user import User
from app.schemas.common import MessageResponse, PaginatedResponse
from app.schemas.user import UserCreate, UserResponse, UserUpdate
from app.services.user_service import UserService
router = APIRouter()
@router.post(
"/",
response_model=UserResponse,
status_code=status.HTTP_201_CREATED,
summary="Create user",
dependencies=[Depends(get_current_superuser)],
)
async def create_user(
user_data: UserCreate,
user_service: Annotated[UserService, Depends(get_user_service)],
db: Annotated[AsyncSession, Depends(get_db)],
) -> UserResponse:
"""
Create a new user (admin only).
Args:
user_data: User creation data
user_service: User service
db: Database session
Returns:
UserResponse: Created user information
Raises:
HTTPException: If user already exists
"""
user = await user_service.create_user(db, user_data=user_data)
return UserResponse.model_validate(user)接口开发阶段要点
- 数据模型输入:将数据库设计和业务需求提供给AI作为上下文
- 代码规范指导:使用包含团队编码规范的提示词模板
- 现有代码借鉴:搜索并引用项目中已有的类似实现作为参考模板
- 分层代码生成:让AI按照Repository-Service-Controller分层生成代码
- 代码评审优化:对AI生成的代码进行review并要求优化改进
- 测试用例生成:让AI同时生成对应的单元测试代码
- 错误处理完善:要求AI补充完整的异常处理和边界情况
第四阶段:文档生成
接口开发完成后,需要生成完整的API文档。使用以下AI提示词来自动生成标准化文档:
📖 API文档生成AI提示词
# API接口文档生成提示词
你是API文档生成专家。将提供的接口代码转换为标准API文档,包含以下内容:
## 文档格式
### 接口信息
- **名称**: [接口功能名称]
- **路径**: [方法] [URL]
- **描述**: [功能说明]
- **认证**: [是否需要token]
### 请求参数
**路径参数**
| 参数 | 类型 | 必填 | 说明 | 示例 |
|------|------|------|------|------|
**查询参数**
| 参数 | 类型 | 必填 | 默认值 | 说明 |
|------|------|------|--------|------|
**请求体**
```json
{
"字段名": "类型说明"
}
```
### 响应格式
**成功响应**
```json
{
"code": 200,
"message": "success",
"data": {}
}
```
**错误响应**
```json
{
"code": 400,
"message": "错误信息"
}
```
### 调用示例
```bash
curl -X POST "接口URL" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer token" \
-d '{"参数": "值"}'
```
---
## 要求
1. 参数类型要准确(string/integer/boolean等)
2. 必填参数标明"是",可选参数标明"否"
3. 提供真实可用的示例值
4. 错误码要完整(400/401/404/500等)
请将接口文档生成到docs目录下,并使用markdown格式。# API接口文档生成提示词
你是API文档生成专家。将提供的接口代码转换为标准API文档,包含以下内容:
## 文档格式
### 接口信息
- **名称**: [接口功能名称]
- **路径**: [方法] [URL]
- **描述**: [功能说明]
- **认证**: [是否需要token]
### 请求参数
**路径参数**
| 参数 | 类型 | 必填 | 说明 | 示例 |
|------|------|------|------|------|
**查询参数**
| 参数 | 类型 | 必填 | 默认值 | 说明 |
|------|------|------|--------|------|
**请求体**
```json
{
"字段名": "类型说明"
}
```
### 响应格式
**成功响应**
```json
{
"code": 200,
"message": "success",
"data": {}
}
```
**错误响应**
```json
{
"code": 400,
"message": "错误信息"
}
```
### 调用示例
```bash
curl -X POST "接口URL" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer token" \
-d '{"参数": "值"}'
```
---
## 要求
1. 参数类型要准确(string/integer/boolean等)
2. 必填参数标明"是",可选参数标明"否"
3. 提供真实可用的示例值
4. 错误码要完整(400/401/404/500等)
请将接口文档生成到docs目录下,并使用markdown格式。文档生成阶段要点
- 代码输入分析:将完整的接口代码提供给AI进行分析解析
- 文档模板应用:使用标准化的API文档生成提示词模板
- 批量文档生成:让AI一次性生成多个接口的完整文档
- 示例自动生成:要求AI生成真实可用的curl调用示例和响应数据
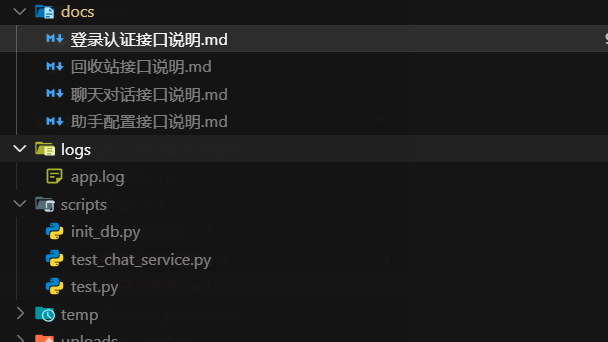
📋 完整开发检查清单
项目架构阶段
- [ ] 技术栈选型确认
- [ ] 项目目录结构搭建
- [ ] 开发规范制定
- [ ] 基础配置文件创建
- [ ] 开发环境搭建
数据库设计阶段
- [ ] 业务实体分析完成
- [ ] 数据库表结构设计
- [ ] 索引和约束设计
- [ ] 数据迁移脚本准备
- [ ] 测试数据准备
接口开发阶段
- [ ] 现有代码库分析完成
- [ ] 通用模式识别和提取
- [ ] AI提示词模板准备
- [ ] API接口设计完成
- [ ] 业务逻辑实现
- [ ] 数据访问层实现
- [ ] 权限控制实现
- [ ] 异常处理完善
- [ ] 代码一致性检查
- [ ] 单元测试编写
文档生成阶段
- [ ] API文档自动生成
- [ ] 接口调用示例准备
- [ ] 错误码说明完整
- [ ] 部署文档准备
- [ ] 使用指南编写
📝 实践总结
智能写作项目采用AI辅助开发模式,完成了完整的后端服务构建:
- 项目架构设计阶段:通过AI提示词确定了技术栈和项目结构,建立了开发规范
- 数据库设计阶段:利用AI生成了标准化的数据库设计和SQL语句,保证了数据模型的一致性
- 接口开发阶段:结合现有代码库分析,实现了符合项目规范的API接口,确保了代码质量和一致性
- 文档生成阶段:建立了自动化API文档生成流程,提高了开发效率
本项目沉淀的AI提示词模板和开发流程,为后续类似项目提供了可复用的方法论和实践经验。通过系统性的代码库分析和模式复用,AI在辅助开发中发挥了更大的价值,既保证了开发效率,又确保了代码质量和团队协作的一致性。